I have some notes about basic stuff and notation for Linear Models.
(Generalized) Linear Model, notation
A quick summary about the notation used in the notes:
\(n\) number of observations in the dataset indexed with \(i\) (\(i = 1, 2, \dots, n\))
\(y_i\) is the observed response for the \(i\)-th observation while \(\mu_i\) is the predicted value from the model (i.e., no errors/residuals)
\(p\) is the number of model coefficients (e.g, \(\beta_1, \dots, \beta_p\)) while \(p' = p + 1\) with 1 being the intercept \(\beta_0\) (if included). \(\mathop{\boldsymbol{\beta}}\underset{p' \times 1}{}\) is the vector of all coefficients.
\(p'\) is also the number of columns in the model matrix. In other terms the number of predictors (considering that categorical predictors with \(k\) levels will create \(k - 1\) columns). \(\mathop{\mathbf{X}}\underset{n \times p'}{}\) is the model matrix with all predictors
\(x_{p_i}\) is the value of the predictor \(x_p\) for the \(i\) th observation
\(\mathbf{y}\) is a vector with all the observations. Each element is \(y_i\) with \(i = 1, 2, \dots, n\)
Understanding distributions
Understanding distributions
A probability distribution of a random variable \(X\) is the set of probabilities assigned to each possible value \(x\).
We can have:
discrete random variables: counts, binary, etc.
continuous random variables: time, weight, etc.
Variables and constants
As any other function, the probability function has constants and variables:
\[
f(x \mid \boldsymbol{\theta})
\]
Where \(x\) is a specific value and \(\theta\) is a vector of variables defining a specific function and \(f(\cdot)\) is a certain function.
Variables and constants, an example
For example, the Gaussian distribution is defined as:
Here the variables are \(\mu\) (the mean) and \(\sigma^2\) (the variance) while \(\pi\) is a constant.
Probability mass and density function
An important distinction is about discrete and continuous random variables:
For discrete random variables \(f(X)\) becomes \(P(X = x \mid \boldsymbol{\theta})\) because we are assigning a certain probability to a discrete variables. The function is called probability mass function (PMF)
For continuous random variables we stick with \(f(X \mid \boldsymbol{\theta})\) and the function is called probability density function (PDF)
The PMF return the probability associated with a certain value of \(x\) while the PDF returns the probability density of a certain value of \(x\)
When we use the distributions, we are usually interested in some properties describing the distribution. These are called moments defined as quantitative measures related to the shape of the function’s graph1. Common moments are:
First moment: is the expected value (i.e., the mean) of the distribution
Second moment: is the variance of the distribution
Third moment: is the skewness
Fourth moment: is the kurtosis
Moments of the distributions
Moments are always the same but the way we actual compute them could change according to the distribution. For example, in the case of Gaussian distribution the mean and the variance are the same as the parameters defining the distribution.
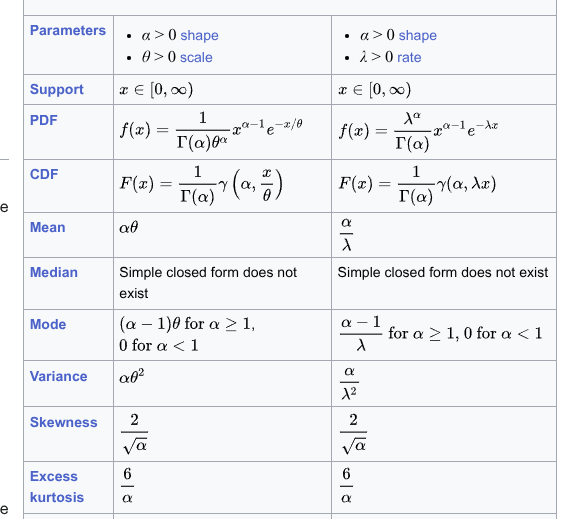
In the Gamma distribution for example, the parameters are the shape \(\alpha\) and scale \(\theta\) or rate \(\lambda\). But the mean is, for example, \(\frac{\alpha}{\lambda}\) and the variance is, for example, \(\frac{\alpha}{\lambda^2}\)
Suggestions for distributions
The Wikipedia pages of the probability distributions are very clear and complete. For the Gamma distribution:
Why is important?
In linear and generalized linear models we generally include predictors on the mean (first moment) of the distribution. Knowing how the mean and is computed from the parameters is crucial to understand the model.
In addition we can note that:
The Gaussian distribution is a very special and ideal case where \(\mu\) and \(\sigma^2\) are directly available and they are independent
Other distributions (e.g., the Gamma) are more complicated due to parameters being used for the mean and the variance (i.e., mean-variance relationship)
Other useful information
In addition to the PDF/PMF we have also:
Cumulative Distribution Function (CDF) usually defined as \(F(x) = P(X \leq x)\). Basically provides the probability of being equal or less compared to a certain \(x\) value. In R, this is the q* (e.g., qnorm()) function.
Quantile Function (QF) is the inverse of the CDF. Usually defined as \(Q(p) = F^{-1}(p)\) where \(p\) is the cumulative probability of interest. Basically it returns the \(x\) value (i.e., the quantile) associated with a certain cumulative probability. In R, this is the p* (e.g., pnorm()) function.
Examples in R, Gaussian PDF
With the Gaussian distribution the PDF is computed using dnorm(x, mean, sd):
Code
x<-seq(-4, 4, 0.01)d<-dnorm(x, mean =0, sd =1)data.frame(x, d)|>ggplot(aes(x =x, y =d))+geom_line(lwd =1, col ="dodgerblue")+xlab("x")+ylab("Density")
Examples in R, Gaussian CDF and QF
Code
cp<-pnorm(x, mean =0, sd =1)qf<-qnorm(cp, mean =0, sd =1)cpp<-data.frame(x, cp)|>ggplot(aes(x =x, y =cp))+geom_line()qfp<-data.frame(x, cp)|>ggplot(aes(x =cp, y =x))+geom_line()cpp+qfp
But…
In Psychology, variables do not always satisfy the properties of the Gaussian distribution. For example:
Reaction times
Percentages or proportions (e.g., task accuracy)
Counts
Likert scales
…
Reaction times
Non-negative and probably skewed data:
Binary outcomes
A series of binary (i.e., bernoulli) trials with two possible outcomes:
Counts
Number of symptoms for a group of patients during the last month:
Should we use a linear model for these variables?
Example 1: passing the exam
Probability of passing the exam as a function of how many hours people study:
nrow(dat)# number of participants#> [1] 50sum(dat$passed)# number of people that have passed the exam#> [1] 21nrow(dat)-sum(dat$passed)# number of people that have not passed the exam#> [1] 29mean(dat$passed)# proportion of people that have passed the exam#> [1] 0.42# study hours and passing the examtapply(dat$studyh, dat$passed, mean)#> 0 1 #> 31.48276 71.33333table(dat$passed, cut(dat$studyh, breaks =4))#> #> (0.903,25.2] (25.2,49.5] (49.5,73.8] (73.8,98.1]#> 0 13 9 6 1#> 1 0 3 8 10tapply(dat$passed, cut(dat$studyh, breaks =4), mean)#> (0.903,25.2] (25.2,49.5] (49.5,73.8] (73.8,98.1] #> 0.0000000 0.2500000 0.5714286 0.9090909
Example 1: passing the exam
Let’s plot the data:
Example 1: passing the exam, fitting a linear model
Let’s fit a linear model passing ~ study_hours using lm:
Do you see something strange?
Example 1: passing the exam
A little spoiler, the relationship should be probably like this:
Example 2: number of correct exercises
Another example, the number of solved exercises in a semester as a function of the number of attended lectures (\(N = 100\)):
Basically it describes how the expected value (i.e., the mean, the first moment) \(\mu\) of the chosen distribution (the random component) varies according to the predictors.
Link Function
The link function\(g(\cdot)\) is an invertible function linking the expected value (i.e., the mean, the first moment) \(\mu\) of the random component with the systematic component \(\boldsymbol{\eta} = \mathbf{X}\boldsymbol{\beta}\).
The simplest link function is the identity link where \(g(\mu) = \mu\) and corresponds to the standard linear model. In fact, the linear regression is just a GLM with a Gaussian random component and the identity link function.
Main distributions and link functions
Family
Link
Range
`gaussian`
identity
$$(-\infty,+\infty)$$
`gamma`
log
$$(0,+\infty)$$
`binomial`
logit
$$\frac{0, 1, ..., n_{i}}{n_{i}}$$
`binomial`
probit
$$\frac{0, 1, ..., n_{i}}{n_{i}}$$
`poisson`
log
$$0, 1, 2, ...$$
Relevant distributions
Bernoulli distribution
A single Bernoulli trial is defined as:
\[
f(x, p) = p^x (1 - p)^{1 - x}
\]
Where \(p\) is the probability of success and \(k\) the two possible results \(0\) and \(1\). The mean is \(p\) and the variance is \(p(1 - p)\)
Binomial distribution
The probability of having \(k\) success (e.g., 0, 1, 2, etc.), out of \(n\) trials with a probability of success \(p\) (and failing \(q = 1 - p\)) is:
\[
f(n, k, p)= \binom{n}{k} p^k(1 - p)^{n - k}
\]
The \(np\) is the mean of the binomial distribution and \(np(1 - p)\) is the variance. The binomial distribution is just the repetition of \(n\) independent Bernoulli trials.
Bernoulli and Binomial
A classical example for a Bernoulli trial is the coin flip. In R:
n<-1p<-0.7rbinom(1, n, p)# a single bernoulli trial
# generate k (success)n<-50# number of trialsp<-0.7# probability of successrbinom(1, n, p)#> [1] 31# let's do several experiments (e.g., participants)rbinom(10, n, p)#> [1] 41 36 33 31 31 36 32 39 34 33# calculate the probability density given k successesn<-50k<-25p<-0.5dbinom(k, n, p)#> [1] 0.1122752# calculate the probability of doing 0, 1, 2, up to k successesn<-50k<-25p<-0.5pbinom(k, n, p)#> [1] 0.5561376
Binomial GLM
The Bernoulli distributions is used as random component when we have a binary dependent variable or the number of successes over the total number of trials:
Accuracy on a cognitive task
Patients recovered or not after a treatment
People passing or not the exam
The Bernoulli or the Binomial distributions can be used as random component when we have a binary dependent variable or the number of successes over the total number of trials.
When fitting a GLM with the binomial distribution we are including linear predictors on the expected value \(\mu\) i.e. the probability of success.
Binomial GLM
Most of the GLM models deal with a mean-variance relationship:
Poisson distribution
The number of events \(k\) during a fixed time interval (e.g., number of new users on a website in 1 week) is:
Where \(k\) is the number of occurrences (\(k = 0, 1, 2, ...\)), \(e\) is Euler’s number (\(e = 2.71828...\)) and \(!\) is the factorial function. The mean and the variance of the Poisson distribution is \(\lambda\).
Poisson distribution
As \(\lambda\) increases, the distribution is well approximated by a Gaussian distribution, but the Poisson is discrete.
The mean-variance relationship can be easily seen with a continuous predictor:
Gamma distribution
The Gamma distribution has several :parametrizations. One of the most common is the shape-scale parametrization:
\[
f(x;k,\theta )={\frac {x^{k-1}e^{-x/\theta }}{\theta ^{k}\Gamma (k)}}
\] Where \(\theta\) is the scale parameter and \(k\) is the shape parameter.
Gamma distribution
ggamma(mean =c(10, 20, 30), sd =c(10, 10, 10), show ="ss")
Gamma \(\mu\) and \(\sigma^2\)
The mean and variance are defined as:
\(\mu = k \theta\) and \(\sigma^2 = k \theta^2\) with the shape-scale parametrization
\(\mu = \frac{\alpha}{\beta}\) and \(\frac{\alpha}{\beta^2}\) with the shape-rate parametrization
Another important quantity is the coefficient of variation defined as \(\frac{\sigma}{\mu}\) or \(\frac{1}{\sqrt{k}}\) (or \(\frac{1}{\sqrt{\alpha}}\)).
The Gamma distribution is quite complex, I have some notes with more insigths about the parametrization.
Gamma distribution
Again, we can see the mean-variance relationship:
ggamma(shape =c(5, 5), scale =c(10, 20), show ="ss")
Gamma parametrization
To convert between different parametrizations, you can use the gamma_params() function:
Is not always easy to work with link functions. In R we can use the distribution(link = ) function to have several useful information. For example:
fam<-binomial(link ="logit")fam$linkfun()# link function, from probability to etafam$linkinv()# inverse of the link function, from eta to probability
We are going to see the specific arguments, but this tricks works for any family and links, even if you do not remember the specific function or formula.
Intutive way of writing models
Dunn & Smyth (2018) uses a nice way of presenting models that could be useful. Basically He specifies the random component distribution and then he specified the parameter(s) where we are including the systematic component.
For example, a Generalized Linear Model with the Gaussian family and identity link could be written as:
The \(i\) subscript indicates that that element varies for each observation \(i\) according to the linear predictor \(\eta_i\) after taking the inverse of the link function.
Assumptions
Lack of outliers: All responses were generated from the same process, so that the same model is appropriate for all the observations.
Link function: The correct link function \(g(\cdot)\) is used.
Linearity: All important explanatory variables are included, and each explanatory variable is included in the linear predictor on the correct scale.1
Variance function: The correct variance function \(\mbxo{var}(\mu)\) is used. This is the mean-variance relationship
Dispersion parameter: The dispersion parameter is constant. This is a subtle but important distinction. The variance is not constant in GLMs but the dispersion parameter is. In Gaussian linear models the disperions is the same as the variance.
Independence: The responses \(y_i\) are independent of each other. This is something related to the data collection and data structure
Distribution: The responses \(y_i\) come from the specified distribution.
References
Agresti, A. (2015). Foundations of Linear and Generalized Linear Models. John Wiley & Sons.
Agresti, A. (2018). An Introduction to Categorical Data Analysis. John Wiley & Sons.
Dunn, P. K., & Smyth, G. K. (2018). Generalized Linear Models With Examples in R. Springer.
Faraway, J. J. (2016). Extending the linear model with R: Generalized linear, mixed effects and nonparametric regression models, second edition. Chapman; Hall/CRC. https://doi.org/10.1201/9781315382722
Fox, J. (2015). Applied Regression Analysis and Generalized Linear Models. SAGE Publications.