Gamma GLM
Psychological Sciences
University of Padova
Last modified: 08-12-2025
Gamma distribution

Gamma distribution
Again, we can see the mean-variance relationship:

Gamma parametrization

\(\mu\) and \(\sigma\) parametrization
- Using the
gamma_params()function we can think in terms of \(\mu\) and \(\sigma\) and generate the right parameters (e.g., shape and rate). - Let’s simulate observations from a Gamma distribution with \(\mu = 500\) and \(\sigma = 200\)

\(\mu\) and \(\sigma\) parametrization
Now let’s simulate the difference between two groups. Again fixing the \(\mu_0 = 500\), \(\mu_1 = 600\) and a common \(\sigma = 200\). Let’s plot the empirical densities:

\(\mu\) and \(\sigma\) parametrization
Let’s see the simulated data:

\(\mu\) and shape parametrization
This is common in brms and other packages1. The \(\mu\) is the same as before and the shape (\(\alpha\)) determine the skewness of the distribution. For the Gamma, the skewness is calculated as \(\frac{2}{\sqrt{\alpha}}\).
To generate data, we calculate the scale (\(\theta\)) as \(\frac{\mu}{\alpha}\) (remember that \(\mu = \alpha\theta\))

Skewness - \(\alpha\) relationship
We can plot the function that determine the skewness of the Gamma fixing \(\mu\) and varying \(\alpha\):

Skewness - \(\alpha\) relationship
Compared to the \(\mu\)-\(\sigma\) method, here we fix the skewness and \(\mu\), thus the \(\hat \sigma\) will differ when \(\mu\) change but the skewness is the same. The opposite is also true.
mu <- c(50, 80)
# mu-shape parametrization
y1 <- rgamma(1e6, shape = 10, scale = mu[1]/10)
y2 <- rgamma(1e6, shape = 10, scale = mu[2]/10)
# mu-sigma parametrization
gm <- gamma_params(mean = mu, sd = c(20, 20))
x1 <- rgamma(1e6, shape = gm$shape[1], scale = gm$scale[1])
x2 <- rgamma(1e6, shape = gm$shape[2], scale = gm$scale[2])
par(mfrow = c(1,2))
plot(density(y1), lwd = 2, main = latex("\\mu and \\alpha parametrization"), xlab = "x", xlim = c(0, 250))
lines(density(y2), col = "firebrick", lwd = 2)
legend("topright",
legend = c(latex("\\mu = %s, \\alpha = %s, \\hat{\\sigma} = %.0f, sk = %.2f", mu[1], 10, sd(y1), psych::skew(y1)),
latex("\\mu = %s, \\alpha = %s, \\hat{\\sigma} = %.0f, sk = %.2f", mu[2], 10, sd(y2), psych::skew(y1))),
fill = c("black", "firebrick"))
hatshape <- c(gamma_shape(x1, "invskew"), gamma_shape(x2, "invskew"))
plot(density(x1), lwd = 2, main = latex("\\mu and \\sigma parametrization"), xlab = "x", xlim = c(0, 250))
lines(density(x2), col = "firebrick", lwd = 2)
legend("topright",
legend = c(latex("\\mu = %s, \\sigma = %s, \\hat{\\alpha} = %.0f, sk = %.2f", mu[1], 20, hatshape[1], psych::skew(x1)),
latex("\\mu = %s, \\sigma = %s, \\hat{\\alpha} = %.0f, sk = %.2f", mu[2], 20, hatshape[2], psych::skew(x2))),
fill = c("black", "firebrick"))
\(\mu\) and \(\sigma\) relationship
See https://civil.colorado.edu/~balajir/CVEN6833/lectures/GammaGLM-01.pdf. The \(\sigma = \frac{\mu}{\sqrt{\alpha}}\).

Example: the Simon effect
The Simon effect is the difference in accuracy or reaction time between trials in which stimulus and response are on the same side and trials in which they are on opposite sides, with responses being generally slower and less accurate when the stimulus and response are on opposite sides.
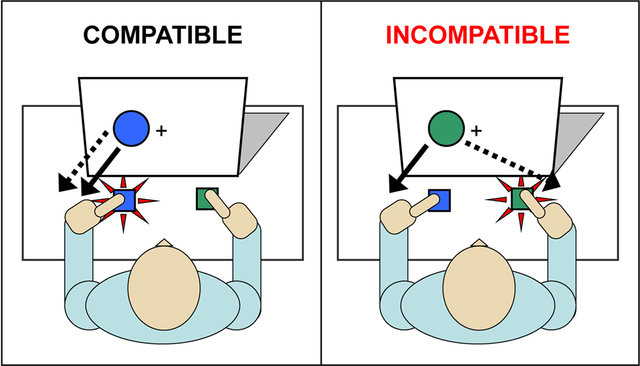
Source: Wildenberg et al. (2010)
Example: the Simon effect
Let’s plot the reaction times. Clearly the two distributions are right-skewed with a difference in location (\(\mu\)). The shape also differs between thus also the skewness is probably different:
ggplot(simon, aes(x = RT, fill = condition)) +
geom_density(alpha = 0.7)
Example: the Simon effect
Plotting the results:
plot(ggeffect(fit))