What we did so far about the two-level model (fixed/equal or random) is combining primary studies summarising each study with an effect size and precision measure.
From https://bookdown.org/MathiasHarrer/Doing_Meta_Analysis_in_R/multilevel-ma.html
In this model, effect sizes (and variances) are considered independent because they are collected on different participants. In other terms each row of a meta-analysis dataset is assumed independent.
In this example from the dat.bcg dataset (?dat.bcg) each row comes from a different study with different participants.
There are situations where effect sizes (and variances) are no longer independent. There are mainly two sources of dependency:
multiple effect sizes within the same paper but with different participants
multiple effect sizes collected on the same pool of participants
The first case refer to a situation where the effect sizes are nested within a paper and given that they will share a similar methodology, same authors, etc. they are likely more similar to each other compared to effect sizes from different papers. We can call this situation a multilevel dataset.
In the second case, the effects are correlated because they are collected on the same pool of participants thus sampling errors are correlated. This is the case where multiple outcome measures are collected or multiple time-points (like a longitudinal design). We can call this situation a multivariate dataset.
Importantly, the two type of meta-analysis will be very similar both formally and from the R implementation point of view but they are clearly distincted from an empirical point of view.
Multilevel meta-analysis
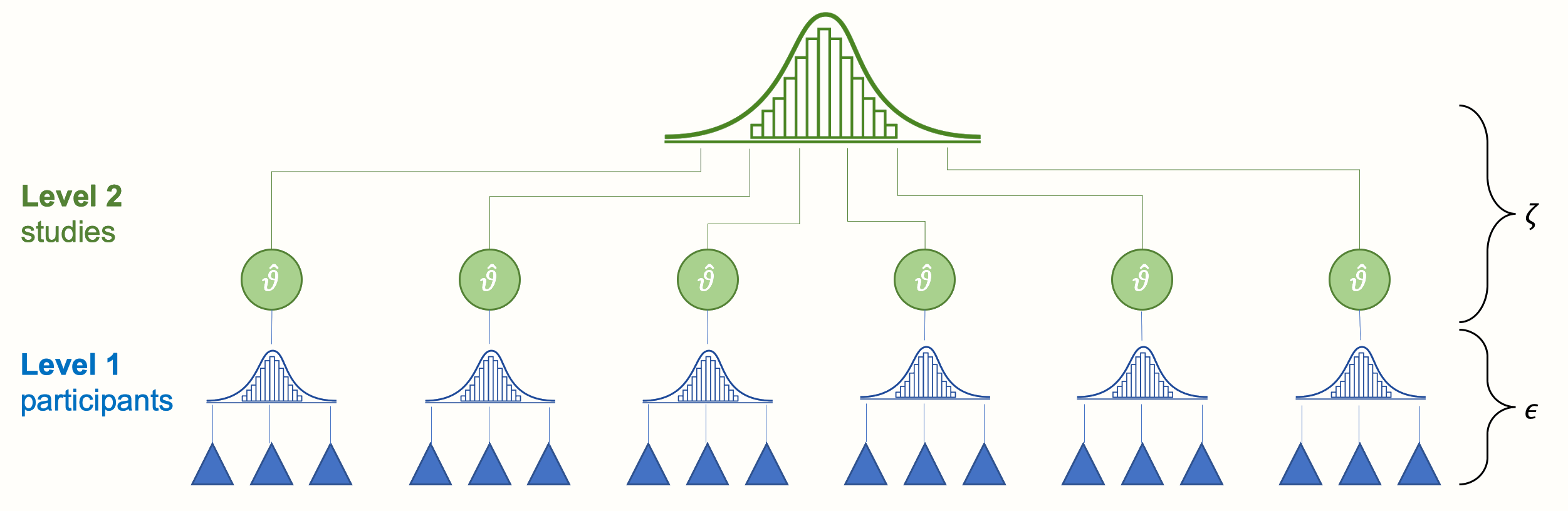
The multilevel data structure can be easily depicted in the figure below.
From https://bookdown.org/MathiasHarrer/Doing_Meta_Analysis_in_R/multilevel-ma.html
Also this picture clearly show the data structure and important parameters:
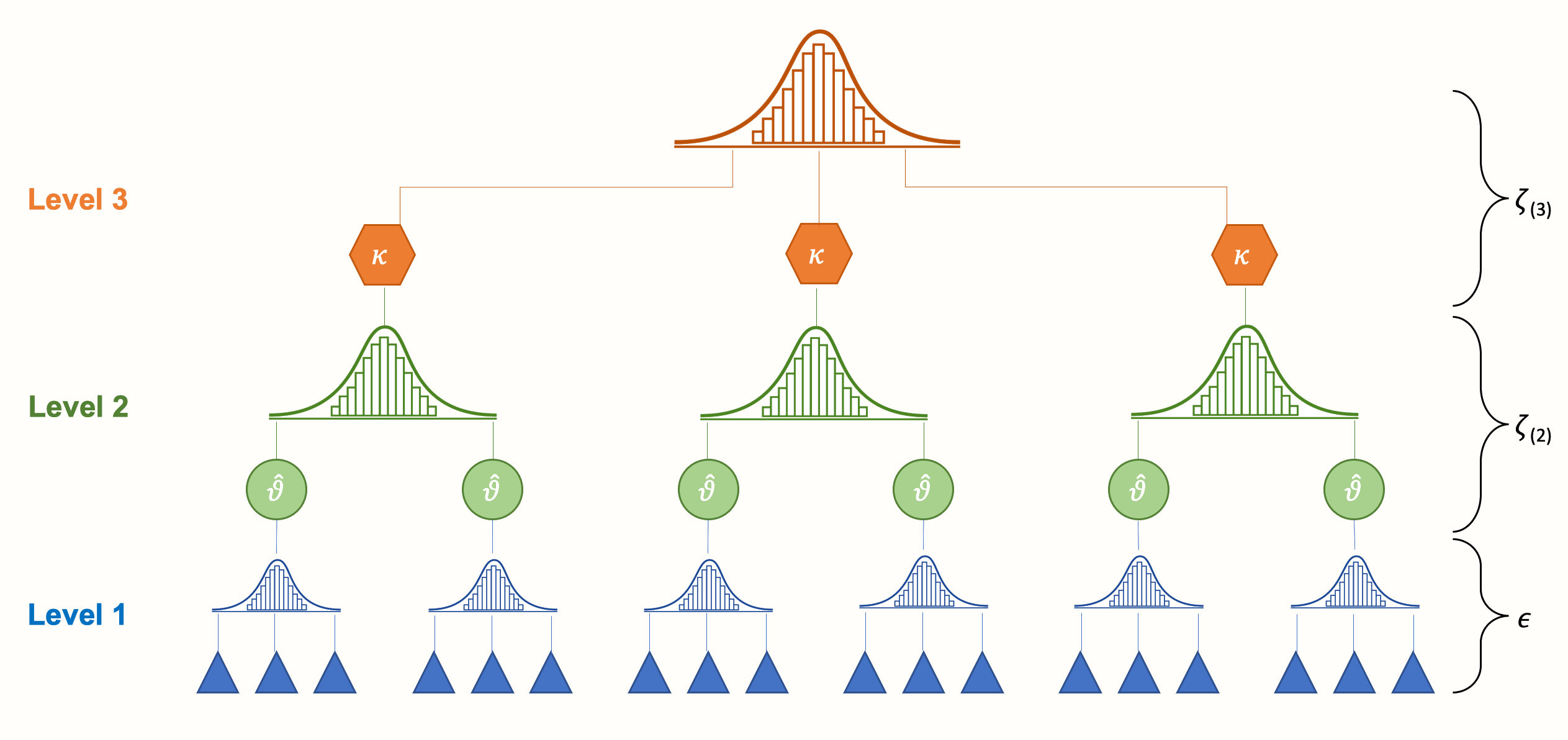
We can have several levels beyond the two-level model but usually common meta-analyses have a maximum of 3-4 levels. For example, it is common in experimental Psychology to have papers with more than one experiment with different participants.
More formally, a three-level model can be written as:
The only addition is an extra source of heterogeneity \(\omega^2\) that can be intepreted as the true heterogeneity between effects nested within the same paper (or whatever is the cluster).
A data structure in this case need to have an index for the cluster and an index for the effect. For example:
Effects within the same paper are more likely to be similar compared to effects between different papers. This degree of similarity is essentially the intraclass correlation defined as the proportion of variance explained by the clustering.
district school study year yi vi
1 11 1 1 1976 -0.180 0.118
2 11 2 2 1976 -0.220 0.118
3 11 3 3 1976 0.230 0.144
4 11 4 4 1976 -0.300 0.144
5 12 1 5 1989 0.130 0.014
6 12 2 6 1989 -0.260 0.014
Here the effect sizes comes from schools (collected on participants) nested within districts. Each district has one or more schools that are likely to have within-district similarity.
We can start by fitting the standard two-level model but here we are ignoring the (possibile) ICC.
fit2l <-rma(yi, vi, data = dat3l)summary(fit2l)
Random-Effects Model (k = 56; tau^2 estimator: REML)
logLik deviance AIC BIC AICc
-16.8455 33.6910 37.6910 41.7057 37.9218
tau^2 (estimated amount of total heterogeneity): 0.0884 (SE = 0.0202)
tau (square root of estimated tau^2 value): 0.2974
I^2 (total heterogeneity / total variability): 94.70%
H^2 (total variability / sampling variability): 18.89
Test for Heterogeneity:
Q(df = 55) = 578.8640, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
0.1279 0.0439 2.9161 0.0035 0.0419 0.2139 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
We need to change the fitting function from rma to rma.mv (mv for multivariate but also multilevel). Essentially we need to specify that we have two clustering levels (beyond the usual first level of the two-level model) using the random = argument.
The two-level model can be fitted also using rma.mv and the result will be practically the same (beyond small numerical differences due to the different algorithm). The two-level model can be written as:
fit2l.mv <-rma.mv(yi, vi, random =~1|study, data = dat3l)summary(fit2l.mv)
Both these models are not entirely correct. We have two options here:
aggregating the effects reducing the three-level structure to a two-level structure
fitting a proper three-level model
For the aggregation, the idea is to essentially perform a two-level fixed effect model for each cluster thus having a (weighted) aggregated effect and sampling variance.
dat3l_l <-split(dat3l, dat3l$district)fit3l_l <-lapply(dat3l_l, function(x) data.frame(predict(rma(yi, vi, data = x, method ="EE"))))dat3l_agg <-do.call(rbind, fit3l_l)fit3l_agg <-rma(pred, se^2, data = dat3l_agg)summary(fit3l_agg)
Random-Effects Model (k = 11; tau^2 estimator: REML)
logLik deviance AIC BIC AICc
-2.0621 4.1242 8.1242 8.7293 9.8384
tau^2 (estimated amount of total heterogeneity): 0.0828 (SE = 0.0397)
tau (square root of estimated tau^2 value): 0.2878
I^2 (total heterogeneity / total variability): 98.10%
H^2 (total variability / sampling variability): 52.60
Test for Heterogeneity:
Q(df = 10) = 415.9203, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
0.1960 0.0900 2.1785 0.0294 0.0197 0.3724 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
This can de done in a more efficient way using the metafor::aggregate() function:
The argument struct = "ID" indicates that sampling errors are independent within each cluster (district).
fit3l_agg <-rma(yi, vi, data = dat3l_agg)summary(fit3l_agg)
Random-Effects Model (k = 11; tau^2 estimator: REML)
logLik deviance AIC BIC AICc
-2.0621 4.1242 8.1242 8.7293 9.8384
tau^2 (estimated amount of total heterogeneity): 0.0828 (SE = 0.0397)
tau (square root of estimated tau^2 value): 0.2878
I^2 (total heterogeneity / total variability): 98.10%
H^2 (total variability / sampling variability): 52.60
Test for Heterogeneity:
Q(df = 10) = 415.9203, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
0.1960 0.0900 2.1785 0.0294 0.0197 0.3724 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The aggregation can also be done within the rma.mv function. Essentially we can provide a (block) variance-covariance matrix instead of the vi element indicating how the effects are correlated within studies.
V <-vcalc(vi = vi, cluster = district, obs = study, rho =0, data = dat3l)rownames(V) <-colnames(V) <-paste0("dist", dat3l$district)round(V, 2)[1:10, 1:10]
At the same time these models assumes that sampling errors are independent (that is probably true) but they are ignoring that the effects could be dependent because they are nested within the same cluster.
The most appropriate model can be specified adding the nested level:
fit3l <-rma.mv(yi, vi, random =~1|district/study, data = dat3l)summary(fit3l)
Multivariate Meta-Analysis Model (k = 56; method: REML)
logLik Deviance AIC BIC AICc
-7.9587 15.9174 21.9174 27.9394 22.3880
Variance Components:
estim sqrt nlvls fixed factor
sigma^2.1 0.0651 0.2551 11 no district
sigma^2.2 0.0327 0.1809 56 no district/study
Test for Heterogeneity:
Q(df = 55) = 578.8640, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
0.1847 0.0846 2.1845 0.0289 0.0190 0.3504 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The argument 1|district/study means that effects (study) are nested within clusters (district).
We can see that the fixed part (Model Results) is the same (in terms of number of parameters not results) as the previous models but now we have two estimated variances, \(\omega^2\) and \(\tau^2\) as the picture above.
Also we can see that the sum of the two variances is similar to the heterogeneity estimated by previous models (slightly higher). The core difference is the fixed part where beyond differences in the estimated effects due to different weights, the standard error is very different.
In particular, the two-level model (on the three-level) dataset is underestimating the standard error of the average effect because is considering each row as independent. The model with aggregation is similar to the three-level model while the model without aggregation is very different.
The difference is related to the ICC parameter:
fit3l$sigma2[1] /sum(fit3l$sigma2)
[1] 0.6652655
The model can be written in a form where the ICC is directly computed:
fit3l.icc <-rma.mv(yi, vi, random =~study|district, data = dat3l)# rma.mv(yi, vi, random = ~study|district, data = dat3l, struct = "CS") # struct = "CS" by defaultsummary(fit3l.icc)
Multivariate Meta-Analysis Model (k = 56; method: REML)
logLik Deviance AIC BIC AICc
-7.9587 15.9174 21.9174 27.9394 22.3880
Variance Components:
outer factor: district (nlvls = 11)
inner factor: study (nlvls = 56)
estim sqrt fixed
tau^2 0.0978 0.3127 no
rho 0.6653 no
Test for Heterogeneity:
Q(df = 55) = 578.8640, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
0.1847 0.0846 2.1845 0.0289 0.0190 0.3504 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
random = ~study|district is defined as inner|outer factors with a compound symmetry structure (struct = CS) by default. The idea is that each study is considered as a different outcome but we estimate a single \(\tau^2\) and a single \(\rho\) that is the correlation between different outcomes/effects. The two models are exactly the same, only with a different parametrization.
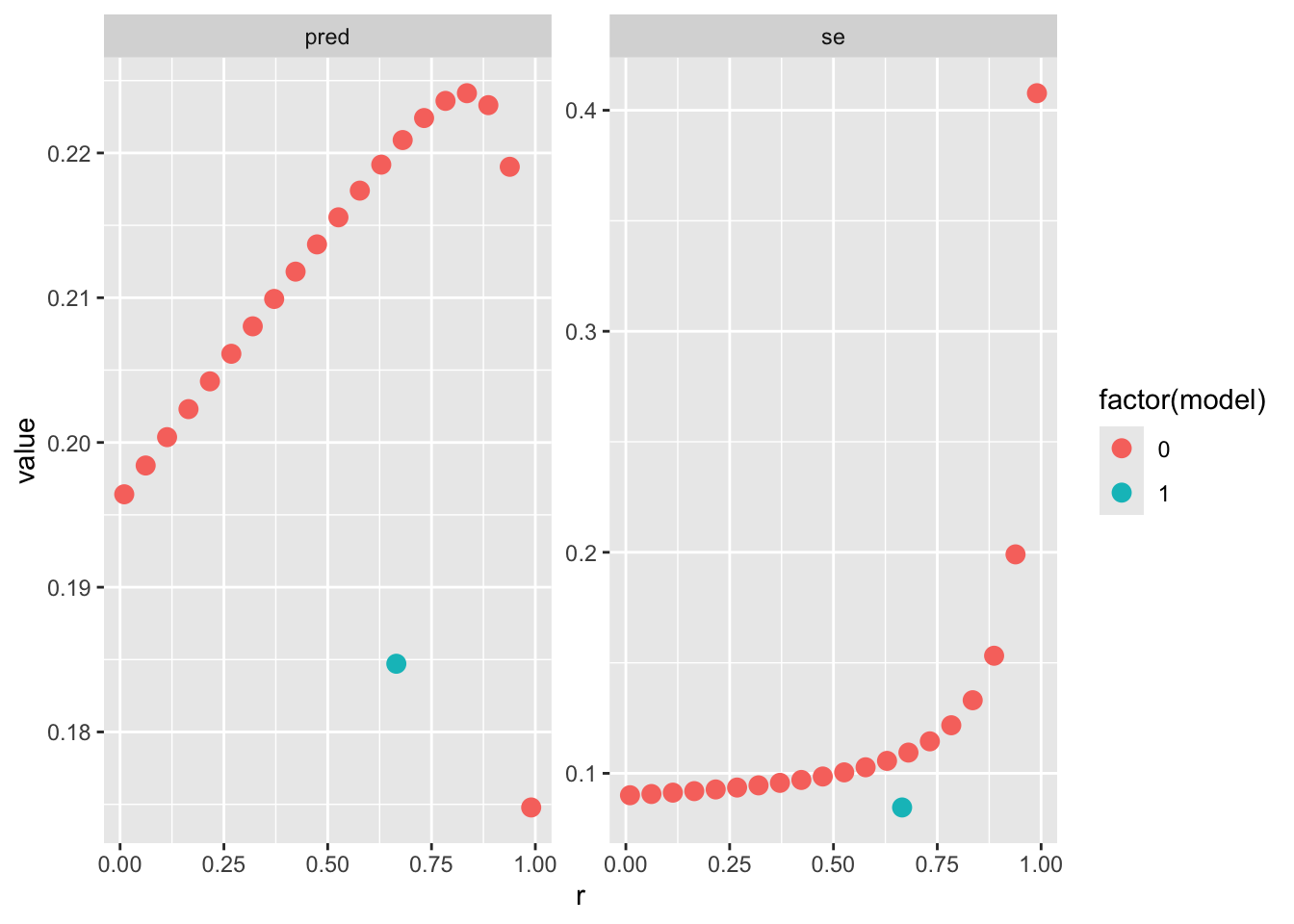
Checking the impact of using a different correlation compared to ICC:
r <-seq(0.01, 0.99, length.out =20)res <-vector(mode ="list", length =length(r))for(i in1:length(r)){ V <-vcalc(vi, cluster = district, obs = study, rho = r[i], data = dat3l) fit <-rma.mv(yi, V, random =~1|district, data = dat3l) fits <-data.frame(predict(fit)) fits$sigma2 <-sum(fit$sigma2) fits$r <- r[i] res[[i]] <- fits}resd <-do.call(rbind, res)resd$model <-0resd3l <-data.frame(predict(fit3l))resd3l$sigma2 <-sum(fit3l.icc$tau2)resd3l$r <- fit3l.icc$rhoresd3l$model <-1resd <-rbind(resd, resd3l)resd |>pivot_longer(c(pred, se)) |>ggplot(aes(x = r, y = value, color =factor(model))) +geom_point(size =3) +facet_wrap(~name, scales ="free")
Clearly, the assumption of the three-level model is that \(\omega^2\) is the same for each cluster thus we are estimating a single \(\omega^2\).
Simulating data
Data simulation again here is very useful to understand the model. We need to generate two vectors of random effects compared to the two-level model. Let’s start with a simple data structure with \(k\) clusters (e.g., papers) each having \(j\) nested effects.
k <-30j <-3dat <-expand.grid(effect =1:j,paper =1:k)dat$id <-1:nrow(dat)head(dat)
es <-0.3tau2 <-0.15omega2 <-0.05(icc <- tau2 / (tau2 + omega2)) # real icc
[1] 0.75
deltai <-rnorm(k, 0, tau2) # k random effectszetaij <-rnorm(nrow(dat), 0, omega2) # k * j (or the number of rows) random effectsdat$deltai <- deltai[dat$paper]dat$zetaij <- zetaij# true effectsdat$thetai <-with(dat, es + deltai + zetaij)head(dat)
Multivariate Meta-Analysis Model (k = 500; method: REML)
logLik Deviance AIC BIC AICc
-194.6568 389.3136 395.3136 407.9514 395.3621
Variance Components:
estim sqrt nlvls fixed factor
sigma^2.1 0.1021 0.3196 100 no paper
sigma^2.2 0.0477 0.2184 500 no paper/study
Test for Heterogeneity:
Q(df = 499) = 2384.5016, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
0.3256 0.0346 9.4164 <.0001 0.2579 0.3934 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
dat$x <-factor(dat$x)contrasts(dat$x) <-contr.sum(2)/2fit3l.lmer <-lmer_alt(y ~ x + (x||paper/study), data = dat)summary(fit3l.lmer)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: y ~ x + (1 + re1.x1 || paper/study)
Data: data
REML criterion at convergence: 143032.5
Scaled residuals:
Min 1Q Median 3Q Max
-4.0132 -0.6696 -0.0016 0.6675 3.9603
Random effects:
Groups Name Variance Std.Dev.
study.paper re1.x1 0.04704 0.2169
study.paper.1 (Intercept) 0.01370 0.1171
paper re1.x1 0.10271 0.3205
paper.1 (Intercept) 0.02670 0.1634
Residual 0.99852 0.9993
Number of obs: 50000, groups: study:paper, 500; paper, 100
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.15610 0.01773 99.00121 8.803 4.43e-14 ***
x1 -0.32488 0.03466 98.99474 -9.374 2.54e-15 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
x1 0.000
Multivariate meta-analysis
As introduced at the beginning the term multivariate is used here for data structure where the dependency arises from multiple effects being collected on the same pool of participants.
For example, in each primary study we did a group comparison (between two independent groups) on two measures. The two effect sizes are correlated because they are measured on the same participants.
The data structure is essentially the same but sampling errors are now correlated within clusters.
The \(\mbox{V}\) matrix is the same that we created with vcalc. Basically is a block variance-covariance matrix with \(k\) matrices (one for each paper/cluster) and number of rows/columns depending on how many outcomes are collected for each paper.
The \(\mbox{T}\) is a \(p\times p\) matrix with \(p\) being the number of outcomes that represents the random-effects matrix. The diagonal is the true heterogeneity across studies for each outcome and the off-diagonal elements are the correlations between different outcomes across studies.
The multivariate model needs \(\mbox{V}\) (as the vi vector) and estimates \(\mbox{T}\) along with the vector of effect sizes.
trial author year ni outcome yi vi v1i v2i
1 1 Pihlstrom et al. 1983 14 PD 0.4700 0.0075 0.0075 0.0030
2 1 Pihlstrom et al. 1983 14 AL -0.3200 0.0077 0.0030 0.0077
3 2 Lindhe et al. 1982 15 PD 0.2000 0.0057 0.0057 0.0009
4 2 Lindhe et al. 1982 15 AL -0.6000 0.0008 0.0009 0.0008
5 3 Knowles et al. 1979 78 PD 0.4000 0.0021 0.0021 0.0007
6 3 Knowles et al. 1979 78 AL -0.1200 0.0014 0.0007 0.0014
7 4 Ramfjord et al. 1987 89 PD 0.2600 0.0029 0.0029 0.0009
8 4 Ramfjord et al. 1987 89 AL -0.3100 0.0015 0.0009 0.0015
9 5 Becker et al. 1988 16 PD 0.5600 0.0148 0.0148 0.0072
10 5 Becker et al. 1988 16 AL -0.3900 0.0304 0.0072 0.0304
Berkey et al. (1998) describe a meta-analytic multivariate model for the analysis of multiple correlated outcomes. The use of the model is illustrated with results from 5 trials comparing surgical and non-surgical treatments for medium-severity periodontal disease. Reported outcomes include the change in probing depth (PD) and attachment level (AL) one year after the treatment. The effect size measure used for this meta-analysis was the (raw) mean difference, calculated in such a way that positive values indicate that surgery was more effective than non-surgical treatment in decreasing the probing depth and increasing the attachment level.
We need to create the V matrix:
V <-vcalc(vi=1, cluster=author, rvars=c(v1i, v2i), data=dat)round(V, 3)
Then the model is the same as the three-level model with the ICC parametrization:
fit.mv0 <-rma.mv(yi, V, random =~outcome|trial, data = dat, struct ="UN")fit.mv0
Multivariate Meta-Analysis Model (k = 10; method: REML)
Variance Components:
outer factor: trial (nlvls = 5)
inner factor: outcome (nlvls = 2)
estim sqrt k.lvl fixed level
tau^2.1 0.3571 0.5976 5 no AL
tau^2.2 0.0356 0.1887 5 no PD
rho.AL rho.PD AL PD
AL 1 - 5
PD -0.6678 1 no -
Test for Heterogeneity:
Q(df = 9) = 784.6078, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
0.2154 0.0592 3.6369 0.0003 0.0993 0.3315 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
What is missing is the fixed part. We are estimating an average outcome effect because we are not differentiating between outcomes. We just need to include outcome as a moderator:
fit.mv1 <-rma.mv(yi, V, mods =~0+ outcome, random =~ outcome|trial, data = dat, struct ="UN")fit.mv1
Multivariate Meta-Analysis Model (k = 10; method: REML)
Variance Components:
outer factor: trial (nlvls = 5)
inner factor: outcome (nlvls = 2)
estim sqrt k.lvl fixed level
tau^2.1 0.0327 0.1807 5 no AL
tau^2.2 0.0117 0.1083 5 no PD
rho.AL rho.PD AL PD
AL 1 - 5
PD 0.6088 1 no -
Test for Residual Heterogeneity:
QE(df = 8) = 128.2267, p-val < .0001
Test of Moderators (coefficients 1:2):
QM(df = 2) = 108.8616, p-val < .0001
Model Results:
estimate se zval pval ci.lb ci.ub
outcomeAL -0.3392 0.0879 -3.8589 0.0001 -0.5115 -0.1669 ***
outcomePD 0.3534 0.0588 6.0057 <.0001 0.2381 0.4688 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Now we have the estimated treatment effect and the \(\mbox{T}\) matrix.
Multivariate as three-level model
Sometimes, the correlations between outcomes are missing and we need to put a plausible value. Van den Noortgate et al. (2013) showed that under some assumptions, fitting a three-level model (thus assuming independence) is actually estimating the effects and standard error in a similar way as the multivariate model including or guessing a correlation.
fit.mv1 <-rma.mv(yi, V, mods =~0+ outcome, random =~ outcome|trial, data = dat, struct ="CS")fit.mv.3l <-rma.mv(yi, vi, mods =~0+ outcome, random =~1|trial/outcome, data = dat)fit.mv1
Van den Noortgate, Wim, José Antonio López-López, Fulgencio Marín-Martínez, and Julio Sánchez-Meca. 2013. “Three-Level Meta-Analysis of Dependent Effect Sizes.”Behavior Research Methods 45 (June): 576–94. https://doi.org/10.3758/s13428-012-0261-6.