2025-04-04
Simulazione
Proviamo a simulare un mixed-model per un esperimento. L’obiettivo è simulare un dataset realistico dove \(k\) soggetti fanno massimo \(n = 240\) trials. Il numero di trials non è lo stesso per soggetto. Il modo di campionare i trial potete deciderlo.
L’esperimento si basa sulla seguente teoria:
Stimoli rilevanti evoluzionisticamente sono elaborati in modo più efficiente rispetto a stimoli meno rilevanti.
Un’ipotesi legata a questo è che ci siano delle categorie (ad esempio i volti) che rispetto ad altre hanno una maggiore rilevanza evoluzionistica. A sua volta, dentro questa categoria, ci sono stimoli con più o meno rilevanza.
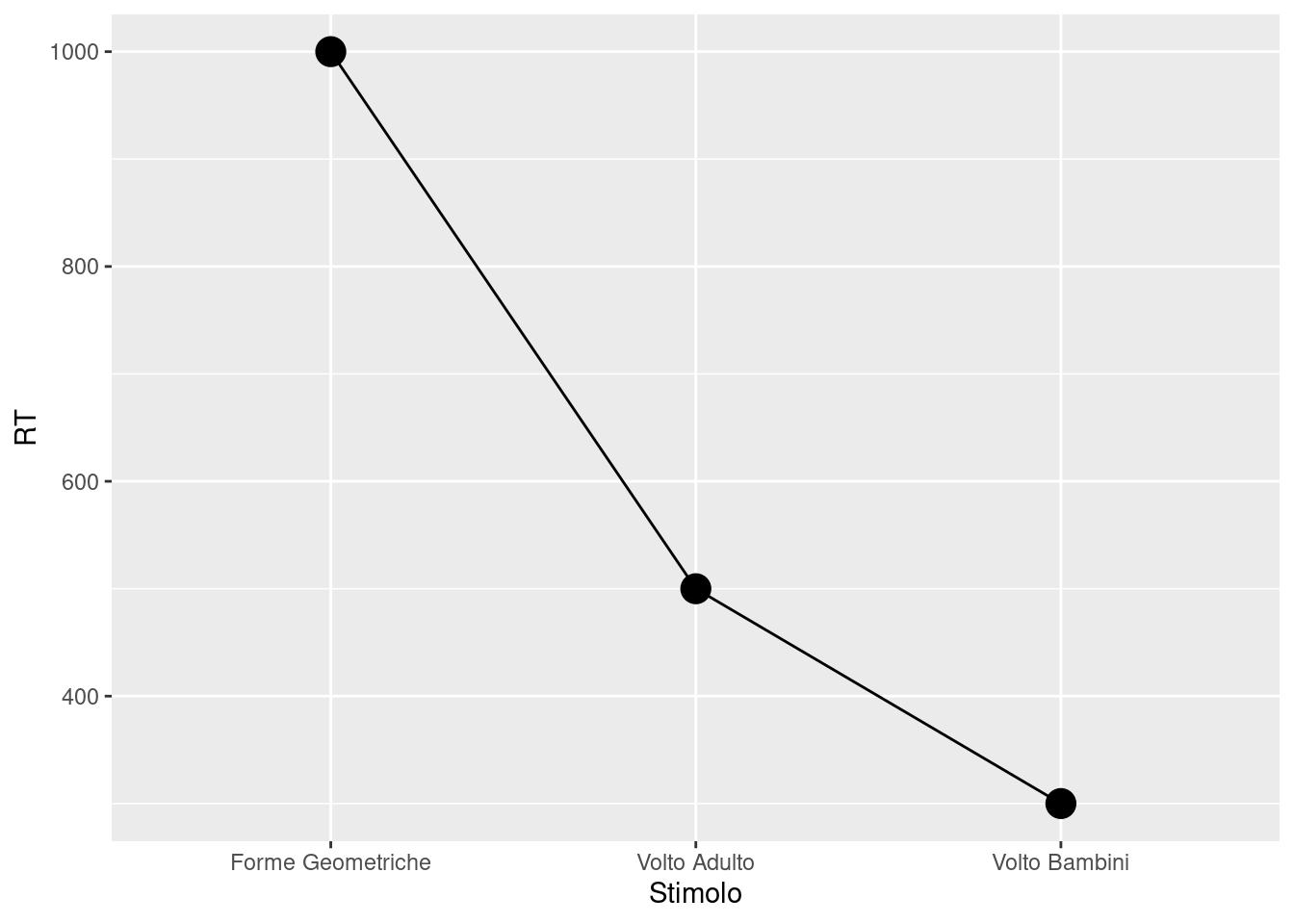
In questo caso si stanno testando i tempi di reazione in laboratorio in risposta a 3 categorie di stimoli:
- volti di persone adulte
- volti di bambini
- forme geometriche
L’ipotesi è che i tempi di reazione siano sistematicamente inferiori per i volti rispetto alle forme geometriche e per i volti di bambini rispetto a quelli adulti.
Per la simulazione è necessario impostare tutti i parametri del modello. Il numero di trials totale è 80 per condizione ma in modo casuale alcuni trial vengono eliminati perchè considerati non validi. La percentuale di dati rimossi da ogni soggetto è sempre inferiore al 30% ma varia da soggetto a soggetto.
Le medie per ogni condizione sono indicate nel grafico. Il grado di skewness nei dati è di 0.5. Per quanto riguarda gli effetti random, scegliete la struttura random che preferite. Al minimo, mettete le intercette random con un valore che vi sembra plausibile.
Ai ricercatori però interessano due contrasti in particolare:
- forme geometriche vs media di volti adulti e bambini
- adulti vs bambini
Impostate una simulazione per generare un dataset realistico che rispetta le regole generali introdotte prima e anche il tipo di variabile. I tempi sono positivi e generalmente asimmetrici.
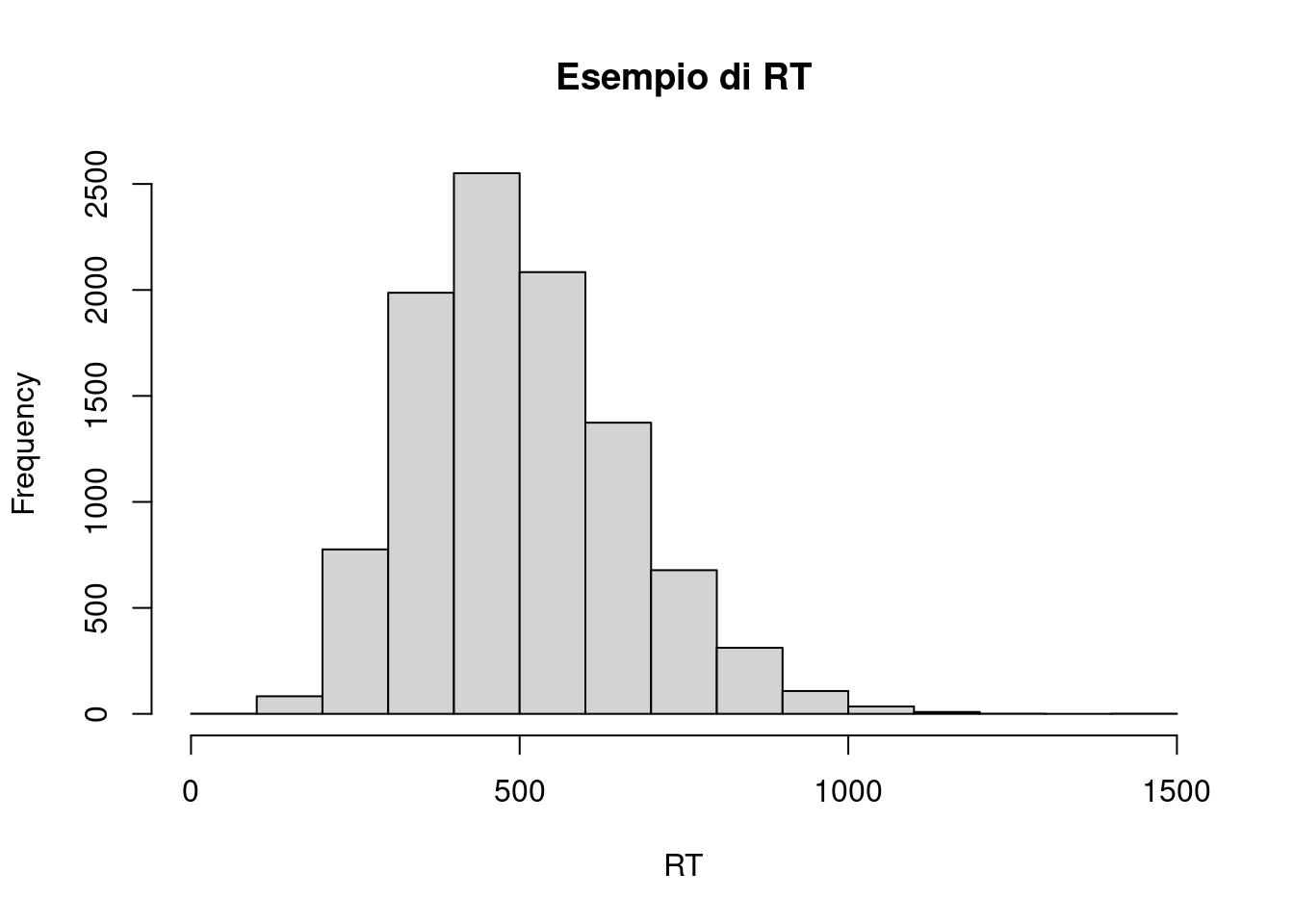
Fate un piccolo report in Quarto o R Markdown dove definite i parametri, codice e qualche grafico di come vengono i dati.
Qualche consiglio:
- partite dal modello che fareste in questo caso
- bisogna trasformare i parametri della distribuzione in qualche modo per fissare queste medie di tempi
- la deviazione standard non è un parametro fisso, partite dalla skewness
- attenzione a
lme4, non sempre funziona benissimo :)