Facciamo un’approfondimento su un’applicazione interessante del modello probit alle decisioni signal detection theory
Assignment
Per oggi facciamo una simulazione, descritta in questo documento
Simulazioni
Abbiamo visto alcune strategie di simulazione, in particolare per calcolare la potenza statistica. Ad esempio nel caso di un t-test assumendo due popolazioni a varianza uguale (\(\sigma = 1\)) e differenza tra le medie \(d = 0.3\) abbiamo:
n <-30# per gruppod <-0.3# effect sizes <-1# pooled standard deviationdf <- n *2-2# degrees of freedomalpha <-0.05nu <- d *sqrt((n * n) / (n + n)) # observed t-value (or non-centrality parameter)tc <-qt(1- alpha/2, df) # critical t-value1-pt(tc, df, nu) +pt(-tc, df, nu) # potenza
[1] 0.2078518
pwr::pwr.t.test(n, d)
Two-sample t test power calculation
n = 30
d = 0.3
sig.level = 0.05
power = 0.2078518
alternative = two.sided
NOTE: n is number in *each* group
Lo stesso lo possiamo vedere come modello lineare:
N <- n *2b0 <-0# intercetta, media gruppo 0b1 <- d # slope, differenza tra i due gruppis <-1# standard deviation residuadat <-data.frame(x =rep(0:1, each = n))dat$y <-rnorm(N, b0 + b1 * dat$x, s)fit <-lm(y ~ x, data = dat)summary(fit)
Call:
lm(formula = y ~ x, data = dat)
Residuals:
Min 1Q Median 3Q Max
-2.15553 -0.49610 0.01076 0.63257 2.38245
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.04311 0.17159 0.251 0.803
x 0.25190 0.24266 1.038 0.304
Residual standard error: 0.9398 on 58 degrees of freedom
Multiple R-squared: 0.01824, Adjusted R-squared: 0.001314
F-statistic: 1.078 on 1 and 58 DF, p-value: 0.3035
In questo caso il parametro di effect size è:
b1 / s # differenza tra gruppi diviso per standard deviation residua
[1] 0.3
coef(fit)[2] /sigma(fit)
x
0.2680318
data.frame(effectsize::cohens_d(y ~ x, data = dat))
Cohens_d CI CI_low CI_high
1 -0.2680318 0.95 -0.7752847 0.2415063
Ovviamente anche la potenza sarà lo stesso.
Nel caso di un disegno pre-post, le osservazioni dello stesso soggetto sono correlate. Per simulare dei dati correlati posso usare il pacchetto MASS::mvrnorm() oppure con la formula di un mixed-model.
r <-0.7R <- r +diag(1- r, 2) # matrice di correlazioneX <- MASS::mvrnorm(n, c(0, d), R)apply(X, 2, mean)
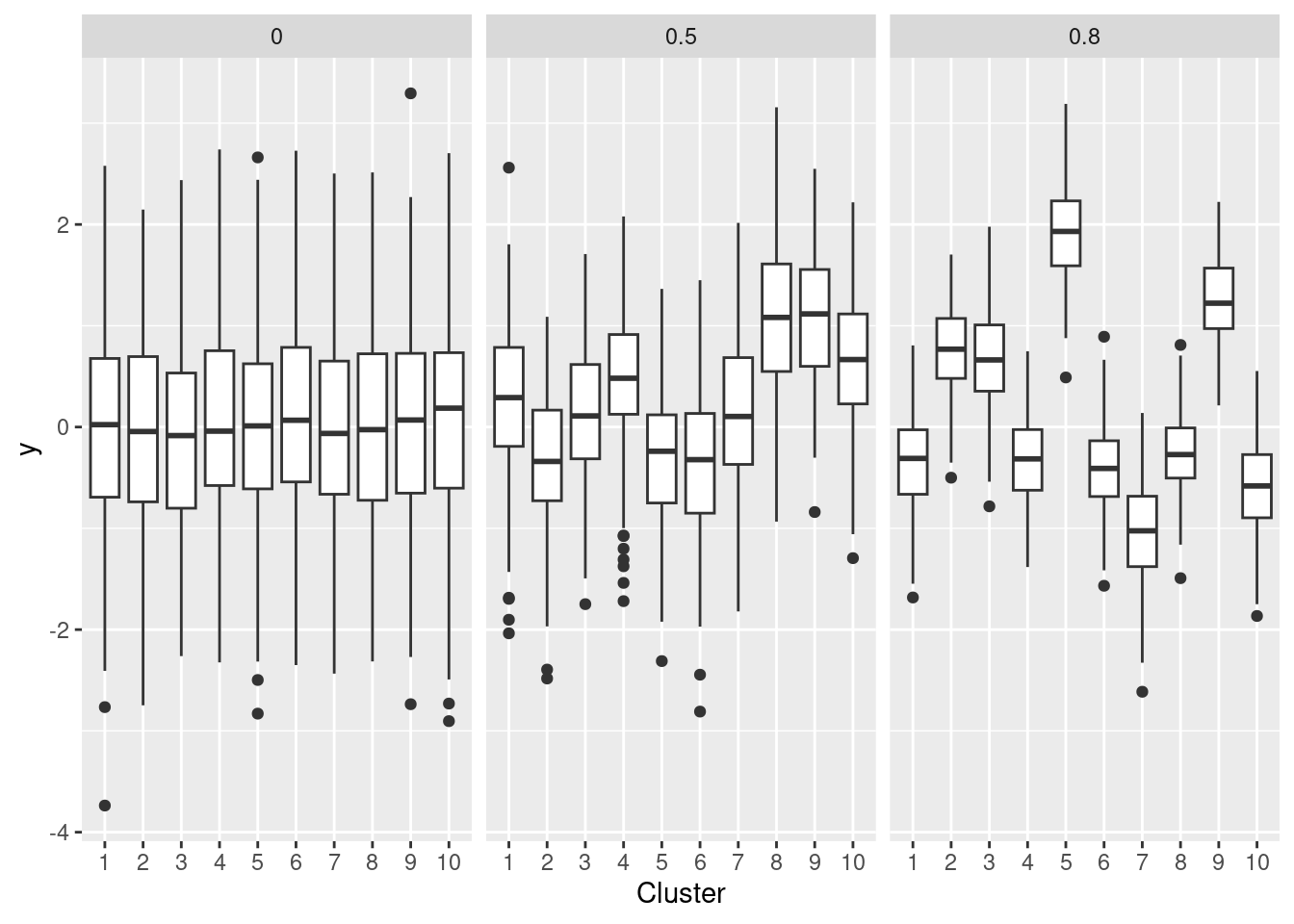
Per quanto riguarda il mixed-model il parametro cruciale è la deviazione standard delle intercette. Possiamo partire dall’Intraclass Correlation Coefficient (ICC) che determina la correlazione tra osservazioni dentro un cluster.
\[
\mbox{ICC} = \rho_{pre-post}
\]\[
\mbox{ICC} = \frac{\sigma^2_{\beta_0}}{\sigma^2_{\beta_0} + \sigma^2_{\epsilon}} \\
\] Se assumiamo che la varianza totale sia uno, allora:
Linear mixed model fit by REML ['lmerMod']
Formula: y ~ x + (1 | id)
Data: dat
REML criterion at convergence: 128.4
Scaled residuals:
Min 1Q Median 3Q Max
-1.7887 -0.5160 0.0831 0.6159 1.4381
Random effects:
Groups Name Variance Std.Dev.
id (Intercept) 0.1978 0.4448
Residual 0.3179 0.5639
Number of obs: 60, groups: id, 30
Fixed effects:
Estimate Std. Error t value
(Intercept) 0.1023 0.1311 0.780
x 0.5246 0.1456 3.603
Correlation of Fixed Effects:
(Intr)
x -0.555
Nei mixed-models è utile capire ed utilizzare l’ICC. Simuliamo dati pre-post con diversi gradi di intraclass correlation (simuliamo più osservazioni di pre-post così è più chiaro il pattern):