Questo lavoro di gruppo richiede di effettuare una design analysis per un esperimento in Psicologia. Un gruppo di ricercatori è interessato a testare l’accuratezza per l’elaborazione di volti con espressione facciale in gruppi clinici e di controllo. L’idea di ricerca riguarda il fatto che in alcuni disturbi psicologici come i disturbi d’ansia ci sia un’elaborazione diversa di stimoli a valenza negativa. In questo caso i ricercatori vogliono confrontare soggetti con e senza disturbo d’ansia nell’elaborazione di volti con espressione facciale negativa (rabbia) e neutra.
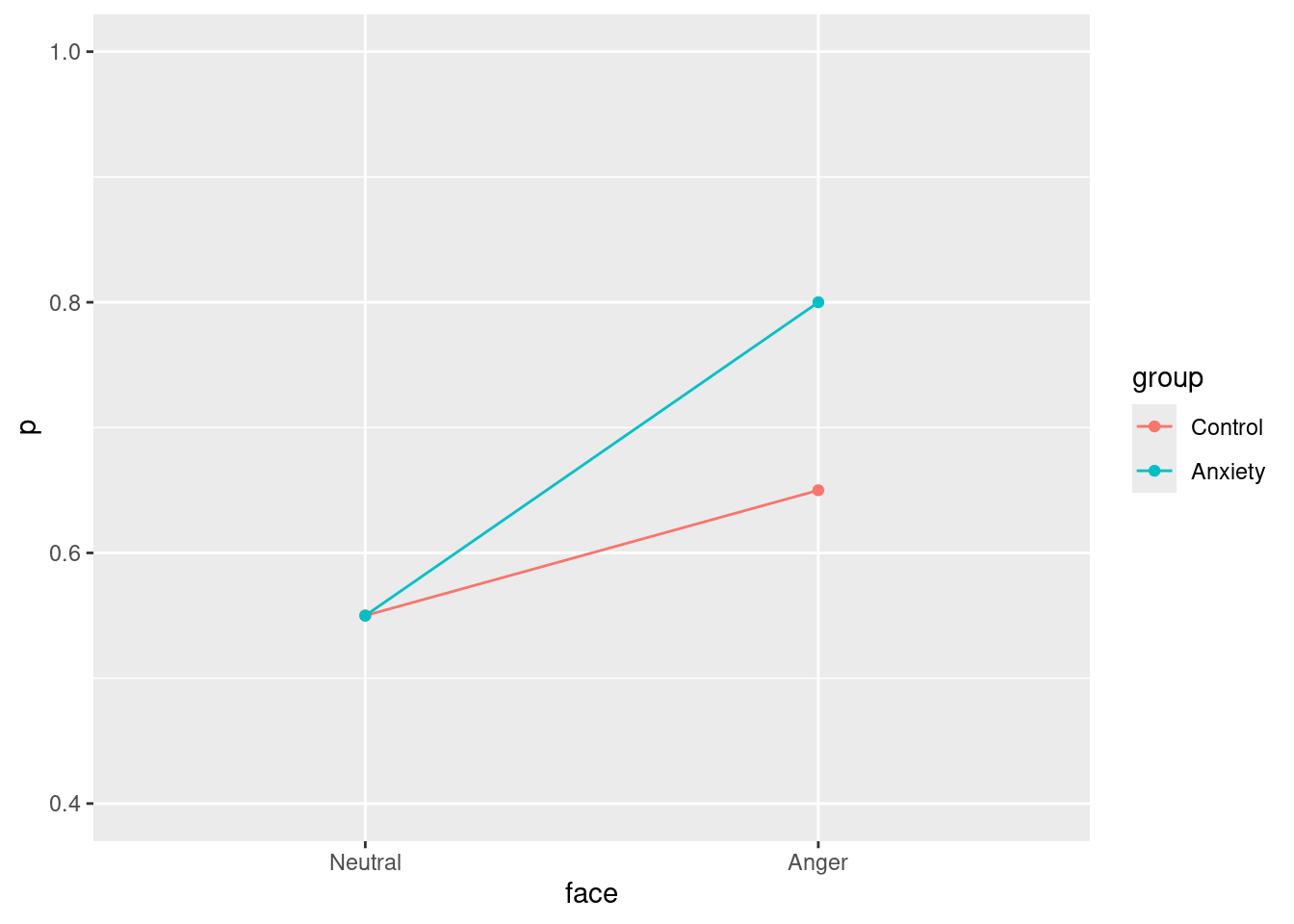
L’ipotesi principale riguarda un’accuratezza maggiore nei soggetti ansiosi rispetto a soggetti non ansiosi solo nel caso di volti con espressione di rabbia. L’ipotesi è rappresentata in Figura 1. Chiaramente i valori effettivi variano in base agli scenari di simulazione. Per semplificare il disegno di simulazione si può assumere a zero la differenza tra gruppi nella condizione di volti neutri.
Oltre all’ipotesi principale i ricercatori vogliono raccogliere le seguenti covariate che dovranno essere inserite nella simulazione e nel modello ma senza essere variate nei vari scenari di simulazione:
sesso: i ricercatori si aspettano in base alla letteratura un’accuratezza maggiore (effetto piccolo) globale nei soggetti di sesso femminile
la percentuale di soggetti di sesso femminile globale è dell’80%
età: l’età è distribuita in modo uniforme tra 20 e 40 anni. Inoltre l’accuratezza globale diminuisce leggermente (un massimo di 5-10% per il range di età) al crescere dell’età
La simulazione deve mostrare la potenza statistica nei vari scenari con l’idea sia di avere un quadro completo che sapere quanti soggetti/trial raccogliere per avere una potenza di circa 80%.
valutare il modello più adeguato per questo tipo di dati e giustificare chiaramente il motivo.
i ricercatori spesso non sanno che anche il numero di trials può aumentare la potenza fissando il numero di soggetti. Trovare un modo chiaro ma formalmente corretto di spiegare questo punto usando grafici, piccole simulazioni, etc.
definire valori plausibili per i parametri
coefficienti fissi dell’esperimento (gruppo ed emozione) e covariate
coefficienti random (quali è plausibile ipotizzare?)
effetturare la simulazione in diversi scenari plausibili:
variando effect size: piccolo, medio e grande
variando numbero di soggetti e numero di trials per soggetto
impostando variabilità tra soggetti negli effetti fissi (i.e., effetti random come intercette e slopes) ad un valore plausibile (non troppo grande o piccolo)
rispetto al numero di simulazione, scegliere un numero secondo voi adeguato cercando di giustificarlo in modo appropriato
rappresentare graficamente i risultati delle varie simulazioni commentando i risultati in modo critico. considerare il bilanciamento tra soggetti e trials.
I ricercatori in psicologia sono abituati ad usare i modelli lineari (t-test, ANOVA, etc.) a prescindere dal tipo di variabile. Questo può creare dei bias nelle stime oppure portare a vere e proprie conclusioni erronee. Fare una ulteriore simulazione per dimostrare quali possono essere i problemi nell’utilizzare un modello lineare e non un GLM per questo tipo di dati. Per questa simulazione si possono omettere le covariate e concentrarsi sulle ipotesi sperimentale. Mostrare almeno una problematica. Suggerimento: valutare gli errori di primo tipo per interazioni testate con modelli lineari quando i dati non rispettano queste assunzioni (come in questo caso).
Suggerimenti
Solitamente i ricercatori in psicologia ragionano con effect sizes standardizzati (e.g., Cohen’s \(d\), standardized mean difference). Provare ad impostare i parametri del modello riguardo le ipotesi sperimentali convertendoli da valori di Cohen’s \(d\). Si veda ad esempio Sánchez-Meca, Marín-Martínez, and Chacón-Moscoso (2003)PDF.
Aspetti generali
Ogni step deve essere accompagnato da una spiegazione narrativa e dove pertinente da rappresentazioni grafiche e tabelle che spieghino in maniera chiara i risultati
Tutti gli step devono essere prodotti in un documento Quarto (html o pdf) riproducibile e self-contained
chi vuole può preparare una presentazione in Quarto da utilizzare durante l’esame
Si faccia particolare attenzione a scrivere codice leggibile, efficiente e che gestisca adeguatamente errori di convergenza e problematiche varie nella simulazione. Cercare di velocizzare il più possibile la simulazione trovando varie strategie online. Per ogni simulazione salvare anche il tempo di computazione.
References
Sánchez-Meca, Julio, Fulgencio Marín-Martínez, and Salvador Chacón-Moscoso. 2003. “Effect-Size Indices for Dichotomized Outcomes in Meta-Analysis.”Psychological Methods 8 (December): 448–67. https://doi.org/10.1037/1082-989X.8.4.448.